Discovery Projects Intro
Discovery Projects Intro
What are Deep Learning Networks?
- Deep Learning is a subfield of machine learning concerned with algorithms inspired by the structure and function of the brain called artificial neural networks.
- Deep Learning networks are the mathematical models that are used to mimic the human brains as it is meant to solve the problems using unstructured data, these mathematical models are created in form of neural network that consists of neurons. The neural network is divided into three major layers that are input layer( first layer of neural network), hidden layer (all the middle layer of neural network) and the output layer(last layer of the neural network.). Based upon these types of data we will deal with these neural networks that are classified as a feed-forward neural network, CNN, RNN, Modular neural network, etc.
Discovery Project
Discovery project is an easy way to build highly customized neural networks without any coding. This feature takes in your dataset and just by answering a few questions through our wizard, you will obtain valuable insights to your data and build a deep learning model usually created by a data scientist. This allows non experts to go from an idea to model in minutes.

Basic Terminologies
1. Model
- A model is a specific representation learned from data by applying some machine learning algorithm. A model is also called hypothesis.
2. Feature
- A feature is an individual measurable property of our data. A set of numeric features can be conveniently described by a feature vector.
3. Target (Label)
- A target variable or label is the value to be predicted by our model.
4. Epoch
- An epoch is a term used in machine learning and indicates the number of passes of the entire training dataset the machine learning algorithm has completed.
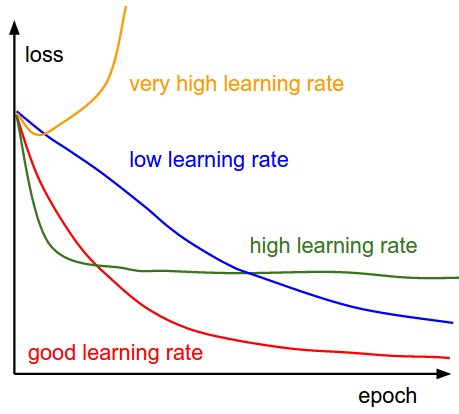
5. Learning Rate
- Learning rate is a tuning parameter in an optimization algorithm that determines the step size at each iteration while moving toward a minimum of a loss function.
6. Batch
- While training a neural network, instead of sending the entire input in one go, we divide in input into several chunks of equal size randomly. Training the data on batches makes the model more generalized as compared to the model built when the entire data set is fed to the network in one go.
7. Activation Function
The activation function translates the input signals to output signals. The output after application of the activation function would look something like f(a*Input+b) where f() is the activation function. Some commonly used activation fumctions are:
7.1. Sigmoid Function
sigmoid(x) = 1/(1+e-x)
7.2. ReLU (Rectified Linear Unit) Function
f(x) = max(x,0)
7.3. Softmax Function
softmax(x) = e^x / sum(e^x)